图的存储方式
首先来看一个例子:
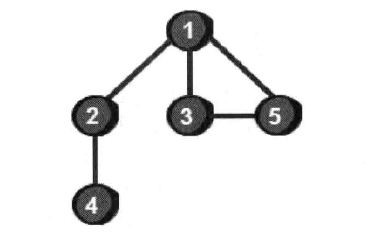
要实现图的遍历,需要先将图存储到一个数据结构中,最常用的存储方法是使用一个二维数组e来存储(邻接矩阵存储法),如下:
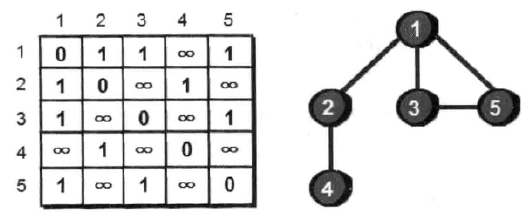
二维数组中第i行第j列表示的就是顶点i到顶点j是否有边,
无向图的邻接矩阵是对称的,实现的时候可以考虑压缩
遍历基本算法
深度优先(DFS)
从1号顶点出发开始遍历这个图,采用深度优先可以得到下图的遍历结果
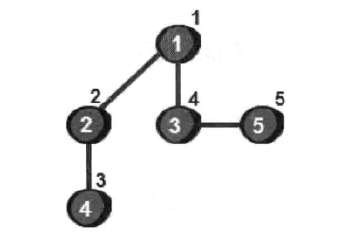
每个顶点上方的数字代表这个顶点在第几步被访问,由于我不喜欢书上那种概念的描述方法,这里放一个我在别处看到的思想概括:
深度优先遍历的主要思想:
首先以一个未被访问的顶点作为起点,沿当前顶点的边走到未访问过的顶点;当没有未访问过的顶点时,回到上一个顶点,继续试探访问别的顶点,直到所有顶点都被访问过。简而言之,就是沿着一条分支遍历直到末端,然后回溯,再沿着另一条进行同样的遍历,知道所有顶点都被访问过。
下面上代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
| public class depthFirst { List<Integer> book; final int[][] edges = { { 0, 1, 1, 9, 1 }, { 1, 0, 9, 1, 9 }, { 1, 9, 0, 9, 1 }, { 9, 1, 9, 0, 9 }, { 1, 9, 1, 9, 0 } }; int scanned = 0; int verticeNum = 5; private void dfs(int vertex) { if (book.contains(vertex)) return; scanned++; book.add(vertex); System.out.println(vertex); if (scanned == verticeNum) return; for (int i = 0; i < verticeNum; i++) { if (edges[vertex][i] == 1) { dfs(i); } } return; } public static void main(String[] args) { depthFirst test = new depthFirst(); test.book = new ArrayList<Integer>(); test.dfs(0); } }
|
代码的具体逻辑已经注释的很清晰这里不再解释,值得归纳的是深度优先算法使用的递归思想;为了加深对思想的理解我总结了DFS算法的三个递归条件:
- 边界条件:已遍历顶点等于总顶点(同一连通图)
- 递归前进段:当前顶点有未遍历过的相邻顶点
- 递归返回段:返回上一级顶点
广度优先(BFS)
同样的我们还看刚才的例子,从1号顶点出发,采用广优先可以得到下图的遍历结果
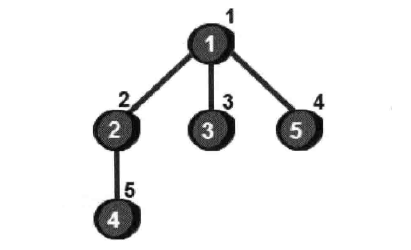
广度优先的主要思想:
首先以一个未被访问过的顶点作为起始顶点,访问所有与其相邻的顶点,然后对每一个相邻的顶点,再访问它们相邻的并且未被访问过的顶点,直到所有顶点都被访问过,遍历结束。
下面上代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41
| public class breadthFirst { List<Integer> book; final int[][] edges = { { 0, 1, 1, 9, 1 }, { 1, 0, 9, 1, 9 }, { 1, 9, 0, 9, 1 }, { 9, 1, 9, 0, 9 }, { 1, 9, 1, 9, 0 } }; int scanned = 0; int verticeNum = 5; Queue<Integer> waitList; public void bfs(int vertex) { waitList.add(vertex); book.add(vertex); scanned++; while (waitList.size() > 0) { int curVertex = waitList.poll(); System.out.println(curVertex); for (int i = 0; i < verticeNum; i++) { if (edges[curVertex][i] == 1 && !book.contains(i)) { scanned++; book.add(i); waitList.add(i); } } if (scanned == verticeNum) break; } while(waitList.size() > 0) { System.out.println(waitList.poll()); } } public static void main(String[] args) { breadthFirst test = new breadthFirst(); test.book = new ArrayList<Integer>(); test.waitList = new LinkedList<Integer>(); test.bfs(0); } }
|
代码中使用了Queue来对遍历的结果进行保存,这是因为队列先进先出的特性与广度优先的逻辑相同,我们可以将广度优先的关键逻辑总结成两句话
- 先访问当前顶点的所有邻接点
- 先访问先被访问的顶点的邻接点(好绕口= =)
上面写的两种算法均使用了ArrayList作为判断顶点是否被访问过的依据,但在遍历的图有两个以上的点入度为0时,或是在遍历森林时,这种方法会加大检索未与起始顶点连通的顶点的复杂度。这里可以考虑使用数组代替ArrayList,当时选择这种方法的原因是因为数组需要在建立时确定长度,但后来一想反正顶点也是二维数组用存的,再用一个数组应该也不会有越界的风险2333,后面具体遇到问题再分析就行。
算法比较
- 深度优先算法:不保留全部节点,占用内存小,有回溯操作(即入栈,出栈),运行速度慢
- 广度优先算法:保留全部节点,占用内存大,无回溯操作(即无入栈、出栈),运行速度快
通常深度优先搜索法不全部保留结点,扩展完的结点从内存中弹出,这样,一般在内存中存储的结点数就是最长的一条路径的值,因此它占用空间较少。所以,当搜索树的结点较多,用其它方法易产生内存溢出时,深度优先搜索不失为一种有效的求解方法。
广度优先搜索算法,一般需存储产生的所有结点,占用的存储空间要比深度优先搜索大得多,因此,程序设计中,必须考虑溢出和节省内存空间的问题。但广度优先搜索法一般无回溯操作,所以运行速度比深度优先搜索要快些。
小结
这篇笔记主要总结了图的邻接矩阵存储方式和两种遍历方法,邻接矩阵表示法通常适用于一般的图的存储,对于边较少,顶点较多的图会浪费许多空间(稀疏矩阵),这种情况可以采用邻接表进行存储,后续会对两种方法进行细致的比对学习;深度优先和广度优先不仅在图的遍历中适用,在遍历二叉树等数据结构时同样适用。
参考阅读:
Java中的递归原理分析
Future belongs to the few of us still wiling to get our hands dirty.